こんな時に製品をご使用下さい
ピーシーキッドアナライザーは、3種類の予測メニューを用意しています。目的に応じて選択してください。
- 1.数量を予測したい
- 回帰問題は数量を予測することです。缶コーヒーの売り上げ本数を予測するなら数量なので、回帰問題になります。ディープラーニングを用いたDNN(Deep Neural Network)回帰、または統計データ解析を用いた回帰分析により数量を予測します。
- 2.確率を予測したい
- 識別問題は0=0%から1=100%までの確率を予測することです。ダイレクトメールの反応を予測するなら、反応なしを0、反応ありを1とすれば識別問題になります。0と1の二択だけではありません。購入商品の色の予測なら、「白」、「灰色」、「黒」といった、三択、四択も識別問題です。ディープラーニングを用いたDNN識別、または統計データ解析を用いたロジスティック回帰分析により確率を予測します。
- 3.時系列データを分析したい
- 時系列問題は、毎日の数量、毎月の数量、毎年の数量のようなデータから、未来の数量を予測することです。毎月の来客数から未来の月々の来客数を予測するなら、時系列問題になります。ディープラーニングを用いたRNN(Recurrent Neural Network)、または統計データ解析を用いたSARIMA(Seasonality Auto-Regressive Integrated Moving Average)分析により時系列データを分析します。
使い方の概要
- (1) メニューの選択
- メニューから分析手法を選択します。
- (2) Excelファイルをアップロード
- 分析してほしいExcelファイルを、サーバにアップロードします。
- (3) 質問に回答
- データに関する質問に答え、分析を開始します。分析手法によっては、計算に時間がかかる場合があります。
- (4) グラフの表示
- 分析手法によっては、分析結果のグラフを表示します。
- (5) Excelファイルをダウンロード
- 分析手法によっては、分析結果をまとめたExcelファイルが、サーバからダウンロードできます。
製品の使い方
「ピーシーキッドアナライザー」の使い方を、具体例を交えてご説明致します。
- ※説明文に現れる企業とデータは、すべて架空のものです。
- ※説明で使われるデータは小規模ですが、これは説明を分かりやすくするためです。一般的に、ディープラーニングは大規模なデータに対して効果を発揮します。
3つの具体例をご紹介します。
具体例1新規店舗の売上を予測したい

レストランや美容院などの多店舗経営を行っている企業において、新規店舗をどの立地に展開するかは悩みどころです。 「より少ない投資でなるべく効率的に収益を上げられる新規店舗を立ち上げたい」と考えたときに、考慮すべき要素は複雑です。 ドミナント戦略も考えながらの店舗展開が必要ですが、ディープラーニングを用いて、「駐車場の有無」「駅からの距離」「敷地面積」「交通量の多寡」など複数の条件を数字にしたexcelファイルを使って容易に売上予測を立てられるのが当社が開発した「ピーシーキッドアナライザー」です。是非、無料でお試しいただける「ピーシーキッドアナライザー」を多店舗展開のリスクヘッジのためにお役立てください。
新規店舗の売上予測の学習データ
| 既存店舗 | 最寄り駅からの時間(分) | 道路の交通量(台/時間) | 駐車場の有無 | 売上高(百万円/年) |
|---|---|---|---|---|
| 既存店舗1 | 7 | 530 | 1 | 100 |
| 既存店舗2 | 14 | 640 | 1 | 140 |
| 既存店舗3 | 6 | 890 | 0 | 160 |
| 既存店舗4 | 10 | 170 | 0 | 90 |
| 既存店舗5 | 0 | 950 | 1 | 190 |
| 既存店舗6 | 8 | 280 | 1 | 60 |
| 途中省略 | ||||
| 既存店舗30 | 7 | 560 | 1 | 100 |
| 既存店舗31 | 9 | 180 | 1 | 40 |
| 既存店舗32 | 7 | 280 | 0 | 140 |
学習データは、既存店舗(32件)とします。
Excelファイルはrestaurant_train.xlsxです。
ここで、駐車場の有無が0か1になっていることに注意してください。 このような二者択一のデータは、駐車場無し=0、駐車場有り=1、と表すとうまくいきます。 あくまでも「有無」なので、2台駐車できる場合も、100台駐車できる場合も、1です。
売上を予測する前に、学習データを眺めてみます。最寄り駅からの時間と売上高の関係については、 最寄り駅からの時間が長いほど売上高は下がります。 道路の交通量と売上高の関係については、 道路の交通量が多いほど売上高は上がります。 駐車場の有無と売上高の関係については、 駐車場がある店舗の平均(102.2)と、 駐車場がない店舗の平均(105.7)は、ほぼ同じです。
新規店舗の売上予測
| 候補店舗 | 最寄り駅からの時間(分) | 道路の交通量(台/時間) | 駐車場の有無 |
|---|---|---|---|
| 候補店舗1 | 10 | 440 | 1 |
| 候補店舗2 | 8 | 340 | 1 |
| 候補店舗3 | 12 | 670 | 0 |
| 候補店舗4 | 9 | 250 | 0 |
予測用データは、新規店舗候補(4件)とします。 Excelファイルはrestaurant_test.xlsxです。
ここで、予測用データには売上高の列がないことに注意してください。 売上高はこれから予測するものなので、予測用データから取り除きます。
具体例2機械の故障確率を予測したい

業務で使用する機械類は予備で使えるものがない、或いは少ない場合、業務維持が困難になる場合があります。例えば会社で使用している大型複合機やコピー機について考えてみたいと思います。複合機・コピー機は、長期間使用すると故障しやすくなりますし、例え長期間使用しなくても集中的な使用などで壊れる場合があります。故障してから急遽サービスマンを派遣してもらうよりは、故障する前に点検をし予防的な部品交換をしたほうが故障等のリスクを最小限に抑えることができます。そこで、複合機・コピー機が稼働しているか故障したかのデータと、使用期間や通算コピー枚数などのデータを学習すれば、稼働しているコピー機の故障確率が予測でき、確率の高い順に点検することができます。今回の学習においては、コピー機の例で学習しますが、全ての企業や店舗等で使用する機械類の故障確率に関しましても応用が可能です。
機械の故障確率の予測の学習データ
| 保有するコピー機 | 使用月数 | 通算枚数 | 故障 |
|---|---|---|---|
| コピー機1 | 99 | 260 | 1 |
| コピー機2 | 22 | 210 | 0 |
| コピー機3 | 72 | 210 | 0 |
| コピー機4 | 98 | 470 | 1 |
| コピー機5 | 55 | 90 | 0 |
| コピー機6 | 84 | 370 | 1 |
| 途中省略 | |||
| コピー機62 | 51 | 180 | 0 |
| コピー機63 | 34 | 530 | 1 |
| コピー機64 | 52 | 400 | 0 |
学習データは、稼働しているか故障したコピー機(64件)とします。 Excelファイルはcopier_train.xlsxです。
ここで、「故障」が0か1になっていることに注意してください。 このような二者択一のデータは、稼働している=0、故障した=1、と表すとうまくいきます。
故障確率を予測する前に、学習データを眺めてみます。使用月数については、故障したコピー機の平均は78.9、 故障していないコピー機の平均は46.4なので、 月数が長いほど故障しやすいです。 通算枚数については、故障したコピー機の平均は377.8、 故障していないコピー機の平均は249.6なので、 枚数が多いほど故障しやすいです。
| 保有するコピー機 | 使用月数 | 通算枚数 |
|---|---|---|
| コピー機2 | 22 | 210 |
| コピー機3 | 72 | 210 |
| コピー機5 | 55 | 90 |
| コピー機7 | 76 | 200 |
| コピー機11 | 42 | 370 |
| コピー機12 | 27 | 240 |
| 途中省略 | ||
| コピー機61 | 28 | 60 |
| コピー機62 | 51 | 180 |
| コピー機64 | 52 | 400 |
機械の故障確率の予測の予測用データ
予測用データは、稼働しているコピー機(28件)とします。 Excelファイルはcopier_test.xlsxです。
ここで、予測用データには故障の列がないことに注意してください。 故障はこれから予測するものなので、予測用データから取り除きます。
具体例3月々の来客数の予測

「ピーシーキッドアナライザー」を用いてテーマパークの月々の来客数を予想することが可能です。来客数の多寡がある程度予測できれば、忙しい時期にはアルバイト数を増員するなど、おおよその採用の年間計画がたてられます。 また、テーマパーク内のレストランの食材の仕入れ計画を立てる場合も、この導き出した月ごとの来客数の予測データを使えば、仕入れ過多による食材のロスを防ぐことができるかもしれません。テーマパークのみならず、映画館や動物園、水族館、大型ショッピングセンターなどの来客予測を立てることも可能です。
月々の来客数の予測の学習データ
| 年月 | 来客数(単位:千人) |
|---|---|
| 2006年1月 | 34 |
| 2006年2月 | 38 |
| 2006年3月 | 36 |
| 2006年4月 | 34 |
| 2006年5月 | 38 |
| 2006年6月 | 48 |
| 途中省略 | |
| 2015年10月 | 129 |
| 2015年11月 | 119 |
| 2015年12月 | 131 |
学習データは、過去の来客数(120か月)とします。 Excelファイルはtheme_park.xlsxです。
参考までに、このExcelファイルの年月は、日付(例えば2006/1/1)を入力してから、表示形式を年月(2006年1月)にしたものです。
予測用データは要りませんが、代わりに予測する期間を入力しますので、36(3年後まで)と決めておきます。
来客数を予測する前に、学習データを眺めてみます。月々の来客数は、不規則に増減しているように見えます。 しかし、1月のみ、2月のみ、…のように、 毎年の同じ月の来客数を比較すると、 来客数は年々増加しています。
実際の使い方をご紹介します。
メニューの選択
「ピーシーキッドアナライザー」とは
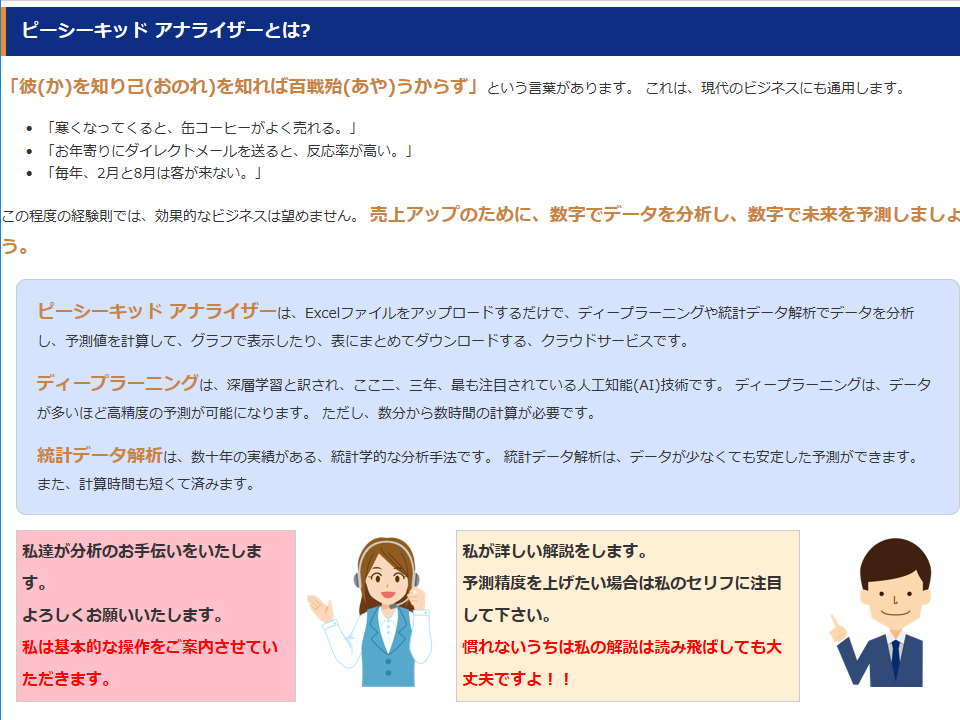
トップページでは、ディープラーニングと統計データ解析について、簡単に説明しています。 説明の仕方は、女性の吹き出しが基本的な内容、男性の吹き出しが詳しい内容です。ピーシーキッドアナライザーを初めて使われる方は、一度お読みください。そして、「次へ」をクリックしてください。
「問題の選択」画面
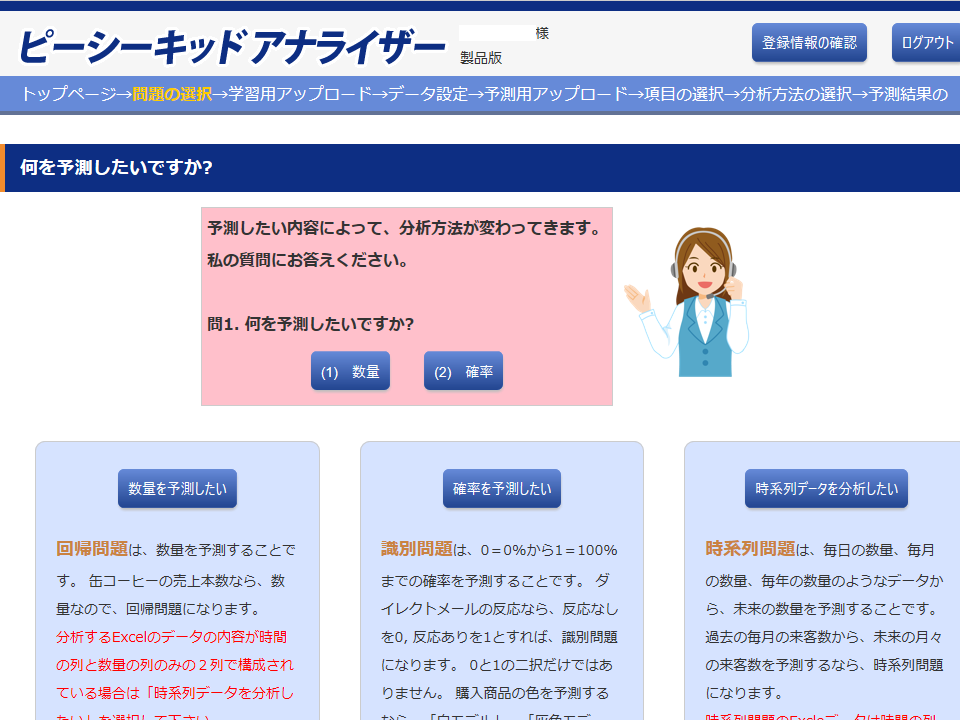
「問題の選択」画面では、以下の3種類のメニューから1つを選択します。どれを選択したらよいか分からない場合、女性の吹き出しの質問に答えてください。
- ▪新規店舗の売上予測のように、時間以外のデータから数量を予測する場合は、「数量を予測したい」を選択します。
- ▪機械の故障確率の予測のように、確率を予測する場合は、「確率を予測したい」を選択します。
- ▪月々の来客数の予測のように、時間から数量を予測する場合は、「時系列データを分析したい」を選択します。
新規店舗の売上を予測する
「学習用アップロード」画面
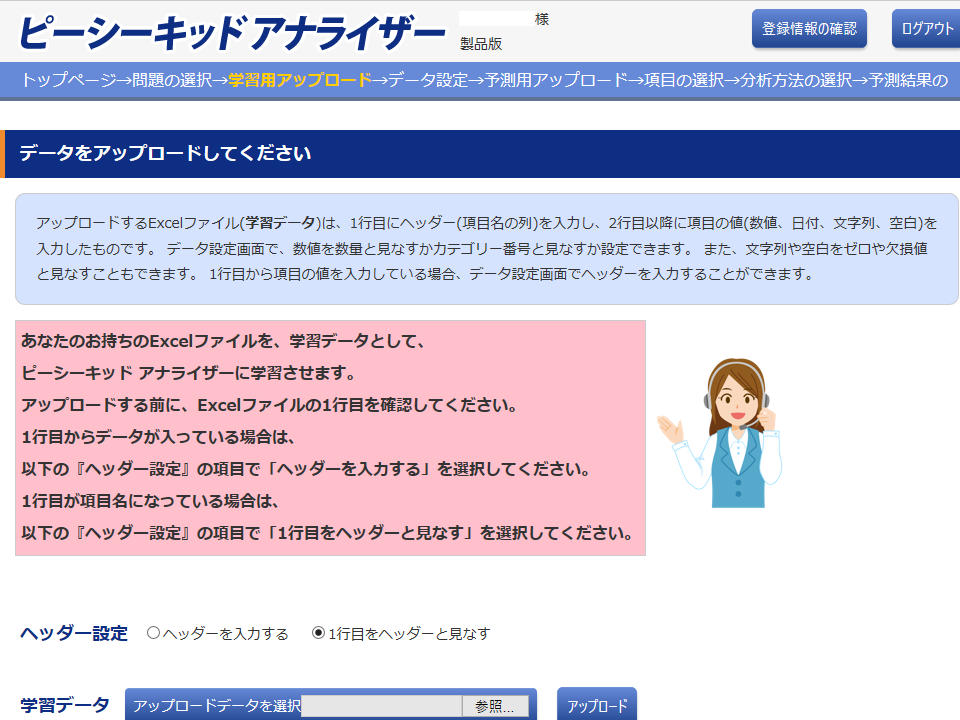
ここでは、新規店舗の売上を予測します。トップページで「次へ」をクリックし、「問題の選択」画面で「数量を予測したい」をクリックしてください。
「学習用アップロード」画面では、学習データが入力されたExcelファイルをアップロードします。 「参照」をクリックして学習ファイル(この場合はrestaurant_train.xlsx)を選択し、「アップロード」をクリックしてください。
「データ設定」画面
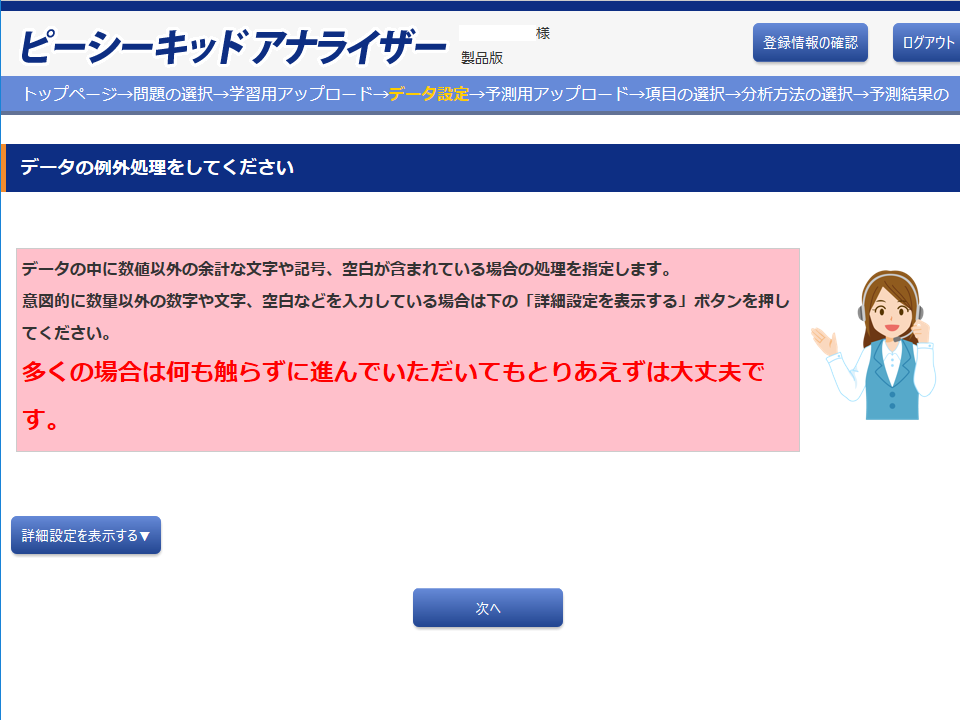
「データ設定」画面では、必要に応じてデータの設定を行います。学習データが以下のとおりであれば、設定は不要なので、「次へ」をクリックしてください。
「予測用アップロード」画面
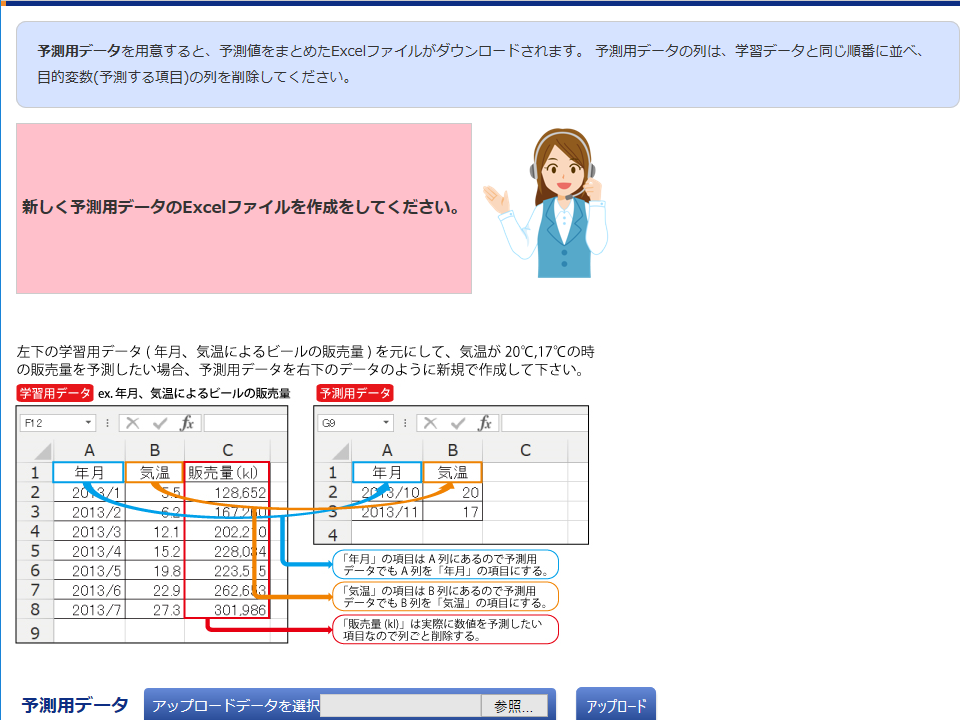
「予測用アップロード」画面では、予測用データが入力されたExcelファイルをアップロードします。「参照」をクリックして予測用ファイル(この場合はrestaurant_test.xlsx)を選択し、「アップロード」をクリックしてください。
「項目の選択」画面
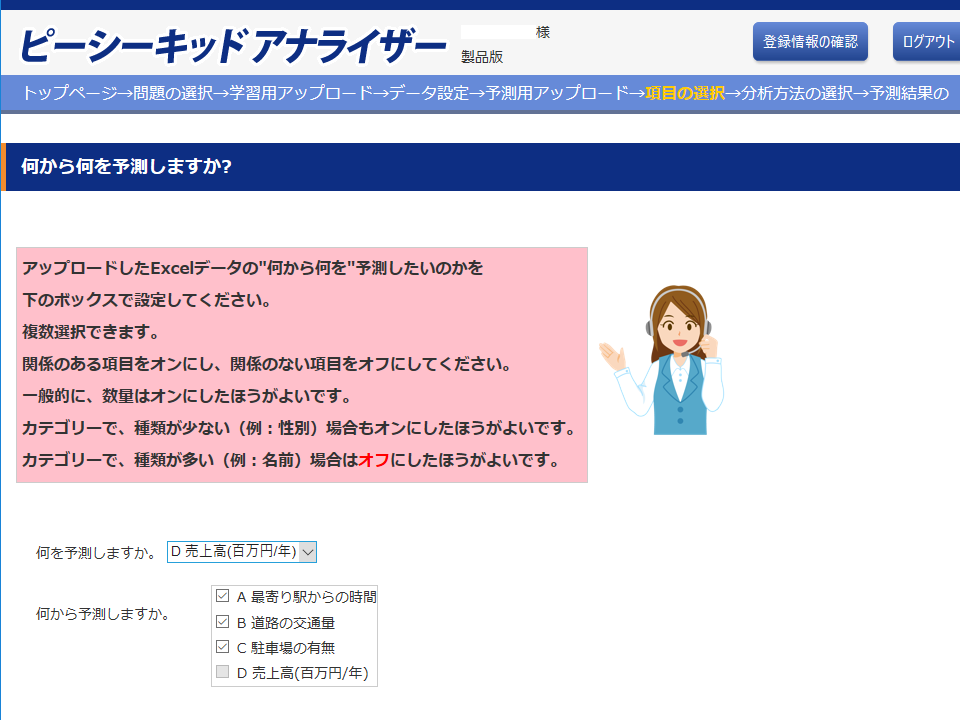
「項目の選択」画面では、「何を予測しますか」(目的変数と言います)と「何から予測しますか」(説明変数と言います)を選択します。何を予測しますか」を変更すると、その項目は「何から予測しますか」でオフになります。何から予測しますか」は、「何を予測しますか」以外のすべてをオンにします。ただし、以下の項目は「オフ」にして下さい。
このデータの場合、「何を予測しますか」を「売上高(百万円/年)」、「何から予測しますか」をそれ以外のすべてとします。
「分析方法の選択」画面
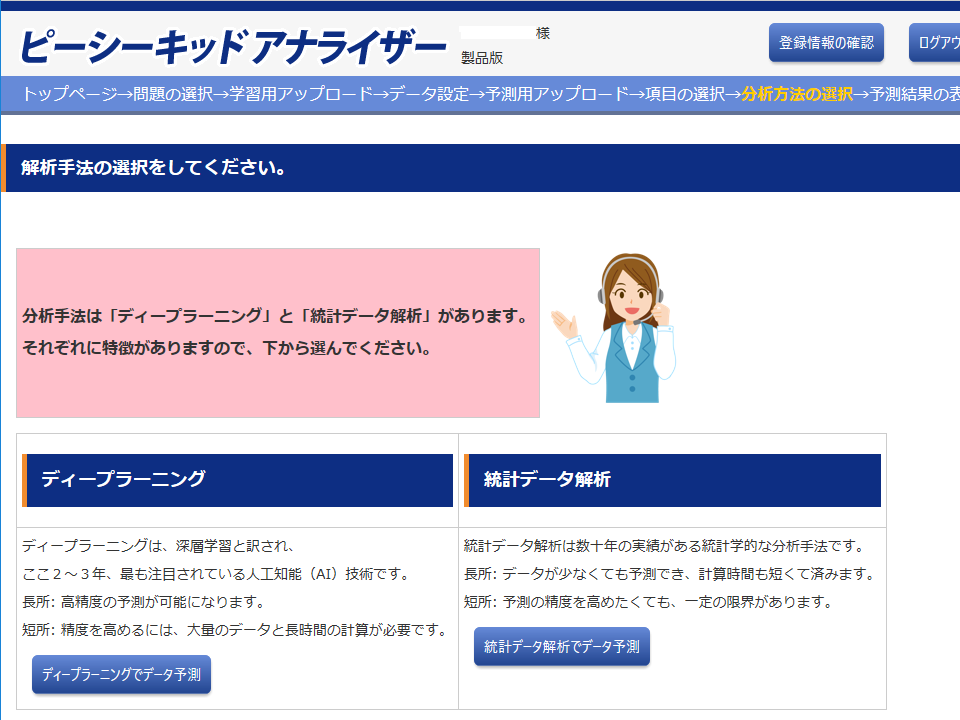
「分析方法の選択」画面では、「ディープラーニング」と「統計データ解析」のどちらかを選択します。 「ディープラーニング」をクリックすると、ディープラーニング(具体的にはリカレントニューラルネットワーク)が始まり、約3分後に結果が表示されます。 「統計データ解析」をクリックすると、統計データ解析(具体的にはSARIMA分析)が始まり、約20秒後に結果が表示されます。
「予測結果の表示」画面
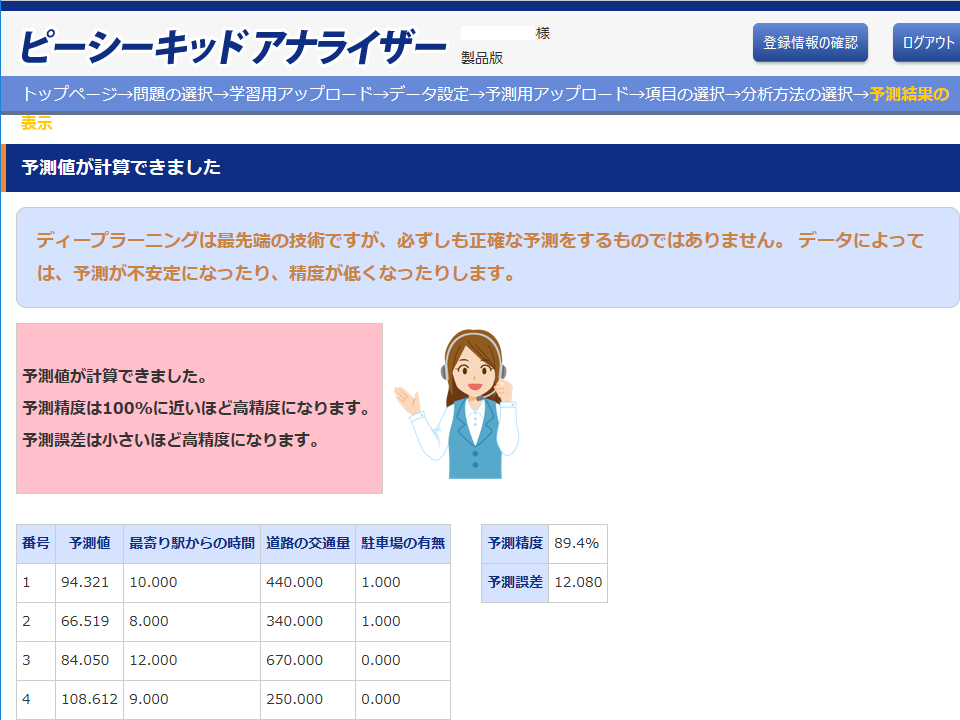
「予測結果の表示」画面では、以下のように予測値が表示されます。 (ディープラーニングの場合、内部で乱数を利用しているため、毎回多少異なる予測値になります。) 「予測結果をダウンロード」をクリックすると、予測値がExcel形式でダウンロードされます。
また、予測精度と予測誤差も表示されます。 予測精度は決定係数で計算され、大きいほど精度が良いです。 このデータの場合、ディープラーニングの予測精度は80%前後、統計データ解析の予測精度は50%前後となり、ディープラーニングの方が精度が良いことが分かります。 一方、予測誤差はRMSE(Root Mean Squared Error)で計算され、小さいほど精度が良いです。 このデータの場合、ディープラーニングの予測誤差は16前後、統計データ解析の予測誤差は26前後となり、やはりディープラーニングの方が精度が良いことが分かります。 このデータは、「駐車場があれば、売上は交通量が多いほど増え、駐車場がなければ、売上は最寄り駅からの時間が短いほど増える。」という特徴を持っています。 統計データ解析では、このような場合分けはうまくできません。 一方、ディープラーニングなら、勝手に場合分けを行って、精度の良い売上予測を行います。
最後に、「トップページに戻る」をクリックすると、トップページに戻ります。
新規店舗の売上予測の結果データ
| 候補店舗 | 予測値 | 最寄り駅からの時間(分) | 道路の交通量(台/時間) | 駐車場の有無 |
|---|---|---|---|---|
| 候補店舗1 | 94.321 | 10 | 440 | 1 |
| 候補店舗2 | 66.519 | 8 | 340 | 1 |
| 候補店舗3 | 84.050 | 12 | 670 | 0 |
| 候補店舗4 | 108.612 | 9 | 250 | 0 |
このデータは、「駐車場があれば、売上は交通量が多いほど増え、駐車場がなければ、売上は最寄り駅からの時間が短いほど増える。」という特徴を持っています。 統計データ解析では、このような場合分けはうまくできません。 一方、ディープラーニングなら、勝手に場合分けを行って、精度の良い売上予測を行います。
機械の故障確率を予測する
「学習用アップロード」画面
ここでは、機械の故障確率を予測します。トップページで「次へ」をクリックし、「問題の選択」画面で「確率を予測したい」をクリックしてください。
「学習用アップロード」画面では、学習データが入力されたExcelファイルをアップロードします。 「参照」をクリックして学習ファイル(この場合はcopier_train.xlsx)を選択し、「アップロード」をクリックしてください。
「データ設定」画面
「データ設定」画面では、必要に応じてデータの設定を行います。学習データが以下のとおりであれば、設定は不要なので、「次へ」をクリックしてください。
「予測用アップロード」画面
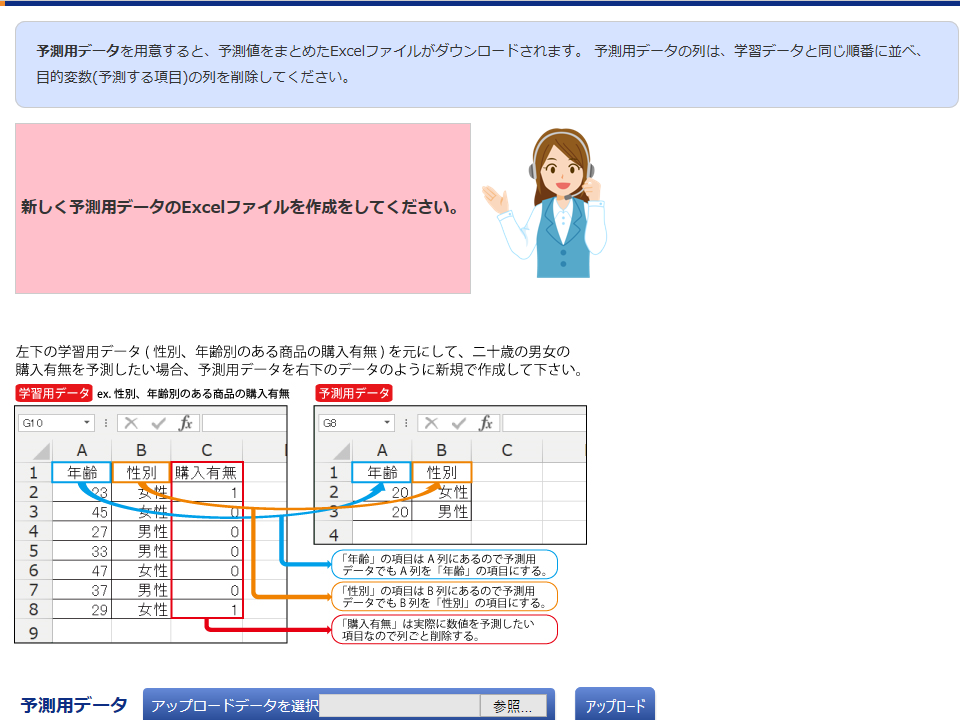
「予測用アップロード」画面では、予測用データが入力されたExcelファイルをアップロードします。 「参照」をクリックして予測用ファイル(この場合はcopier_test.xlsx)を選択し、「アップロード」をクリックしてください。
「項目の選択」画面
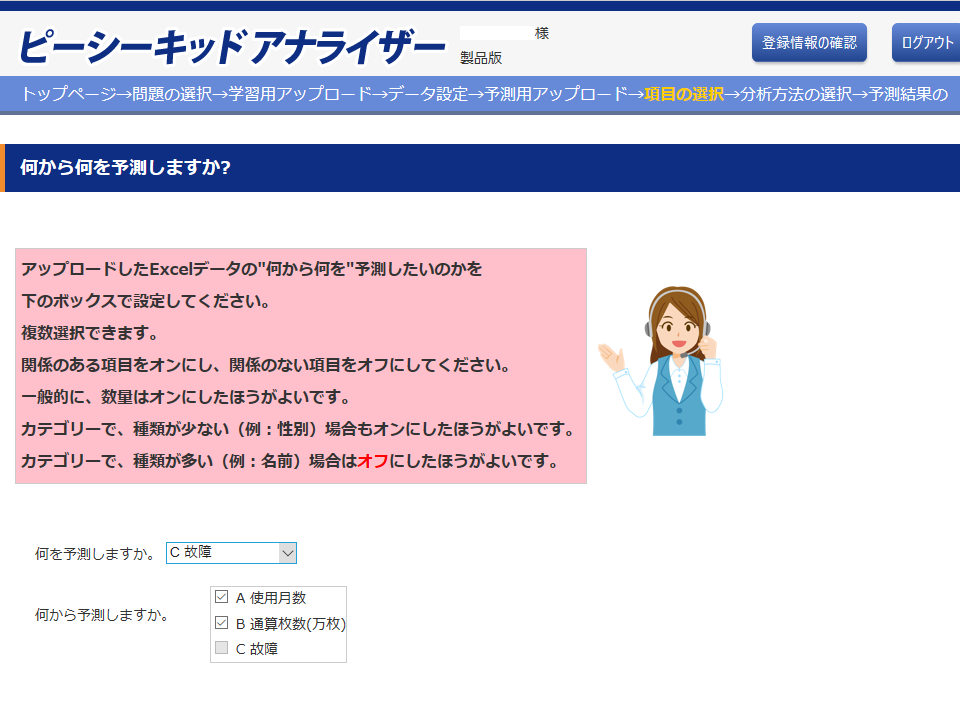
「項目の選択」画面では、「何を予測しますか」(目的変数と言います)と「何から予測しますか」(説明変数と言います)を選択します。 「何を予測しますか」を変更すると、その項目は「何から予測しますか」でオフになります。 「何から予測しますか」は、「何を予測しますか」以外のすべてをオンにします。 ただし、以下の項目はオフにして下さい。
このデータの場合、「何を予測しますか」を「故障」、「何から予測しますか」をそれ以外のすべてとします。
「分析方法の選択」画面
「分析方法の選択」画面では、「ディープラーニング」と「統計データ解析」のどちらかを選択します。 「ディープラーニング」をクリックすると、ディープラーニング(具体的にはディープニューラルネットワーク識別)が始まり、約3分後に結果が表示されます。 「統計データ解析」をクリックすると、統計データ解析(具体的にはロジスティック回帰分析)が始まり、約20秒後に結果が表示されます。
機械の故障確率の予測結果
「予測結果の表示」画面
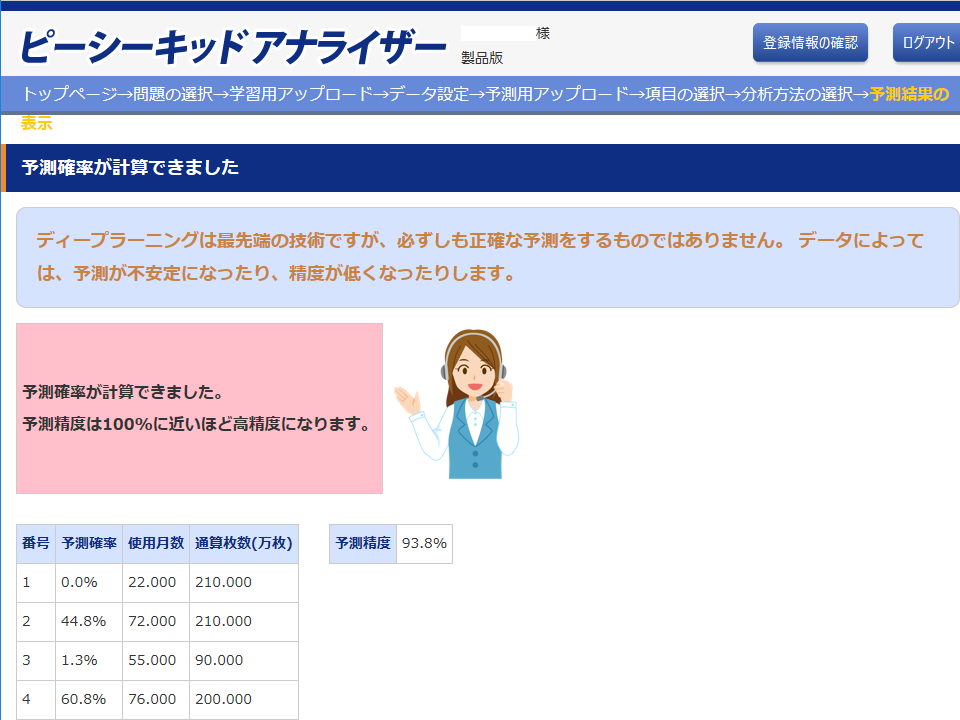
「予測結果の表示」画面では、以下のように予測確率が表示されます。 (ディープラーニングの場合、内部で乱数を利用しているため、毎回多少異なる予測確率になります。) 「予測結果をダウンロード」をクリックすると、予測確率がExcel形式でダウンロードされます。
また、予測精度も表示されます。 予測精度はパーセンテージで計算され、大きいほど精度が良いです。 このデータの場合、ディープラーニングの予測精度は93%前後、統計データ解析の予測精度は90%前後となり、ディープラーニングの方が精度が良いことが分かります。
最後に、「トップページに戻る」をクリックすると、トップページに戻ります。
機械の故障確率の予測結果データ
| 保有するコピー機 | 予測確率 | 使用月数 | 通算枚数(万枚) |
|---|---|---|---|
| コピー機2 | 0.0% | 22 | 210 |
| コピー機3 | 44.8% | 72 | 210 |
| コピー機5 | 1.3% | 55 | 90 |
| コピー機7 | 60.8% | 76 | 200 |
| コピー機11 | 44.5% | 42 | 370 |
| コピー機12 | 0.0% | 27 | 240 |
| 途中省略 | |||
| コピー機61 | 0.0% | 28 | 60 |
| コピー機62 | 1.4% | 21 | 180 |
| コピー機64 | 99.6% | 52 | 400 |
このデータは、「コピー機は、ある一定の期間使用するか、ある一定の枚数をコピーすると、故障しやすくなる。」という特徴を持っています。 統計データ解析では、このような条件の組合せがうまくできません。 一方、ディープラーニングなら、勝手に条件を組み合わせて、精度良く故障の予測を行います。
月々の来客数を予測する
「学習用アップロード」画面
ここでは、月々の来客数を予測します。 トップページで「次へ」をクリックし、「問題の選択」画面で「時系列データを分析したい」をクリックしてください。
「学習用アップロード」画面では、学習データが入力されたExcelファイルをアップロードします。 「参照」をクリックして学習ファイル(この場合はtheme_park.xlsx)を選択し、「アップロード」をクリックしてください。
「データ設定」画面
「データ設定」画面では、必要に応じてデータの設定を行います。学習データが以下のとおりであれば、設定は不要なので、「次へ」をクリックしてください。
「項目の選択」画面
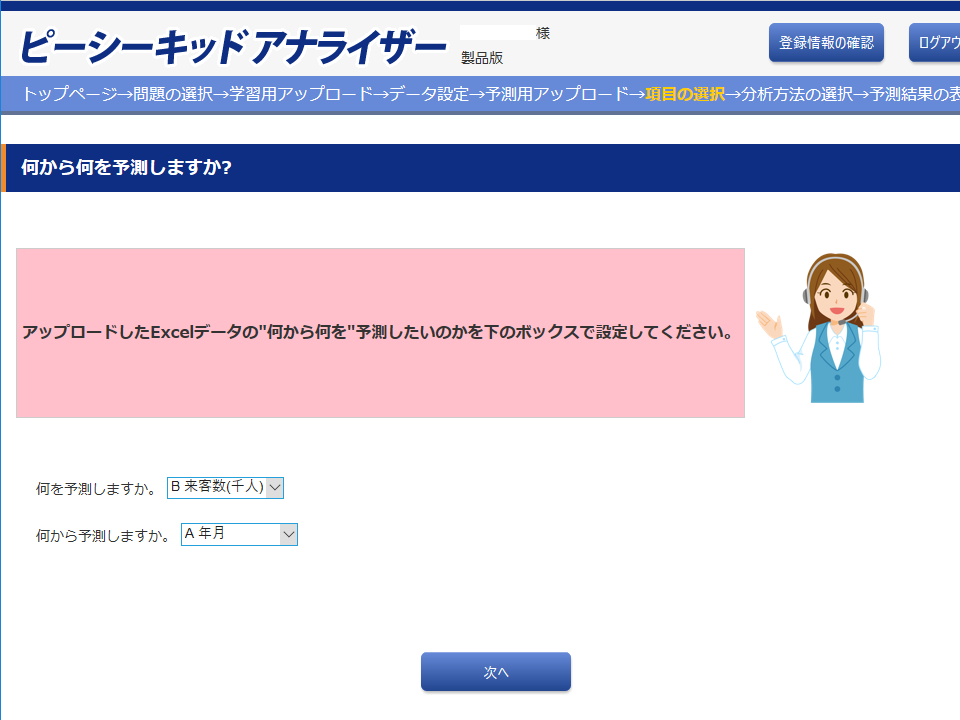
「項目の選択」画面では、「何を予測しますか」(目的変数と言います)と「何から予測しますか」(説明変数と言います)を選択します。 このデータの場合、「何を予測しますか」を「来客数(千人)」、「何から予測しますか」を「年月」とします。
「予測期間の設定」画面

「予測期間の設定」画面では、予測する期間を入力して、「次へ」をクリックします。 学習データが月ごとで、36か月先まで予測したければ、「36」と入力します。
「分析方法の選択」画面
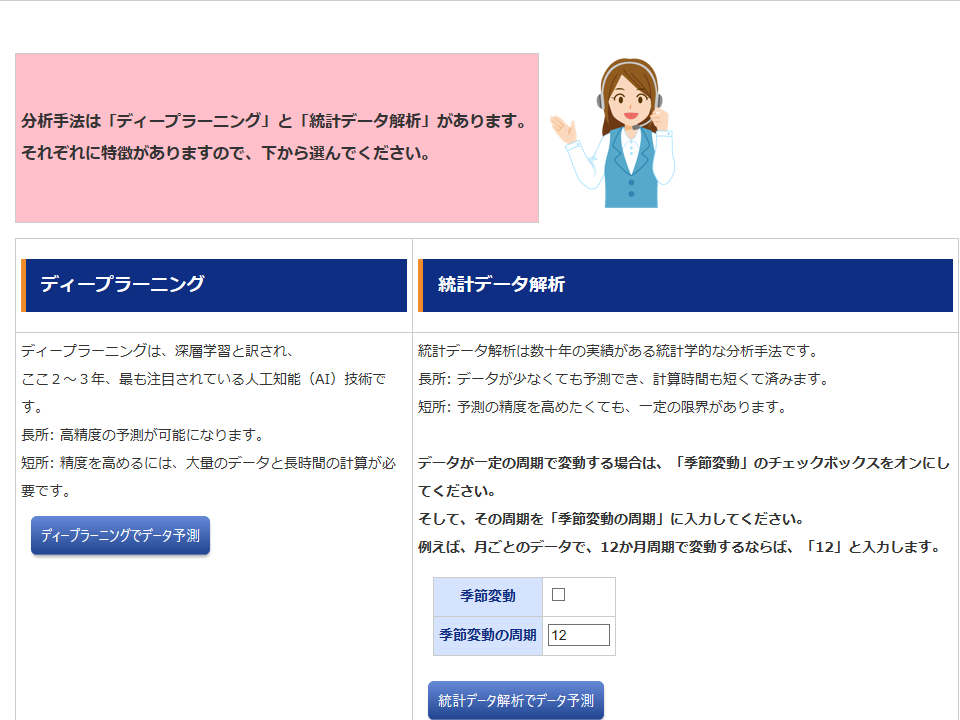
「分析方法の選択」画面では、「ディープラーニング」と「統計データ解析」のどちらかを選択します。 「ディープラーニング」をクリックすると、ディープラーニング(具体的にはリカレントニューラルネットワーク)が始まり、約3分後に結果が表示されます。 「統計データ解析」をクリックすると、統計データ解析(具体的にはSARIMA分析)が始まり、約20秒後に結果が表示されます。 統計データ解析の場合、例えば周期12の季節変動があれば、「季節変動」をオンにし、「季節変動の周期」に「12」と入力します。
月々の来客数の予測結果
「予測結果の表示」画面
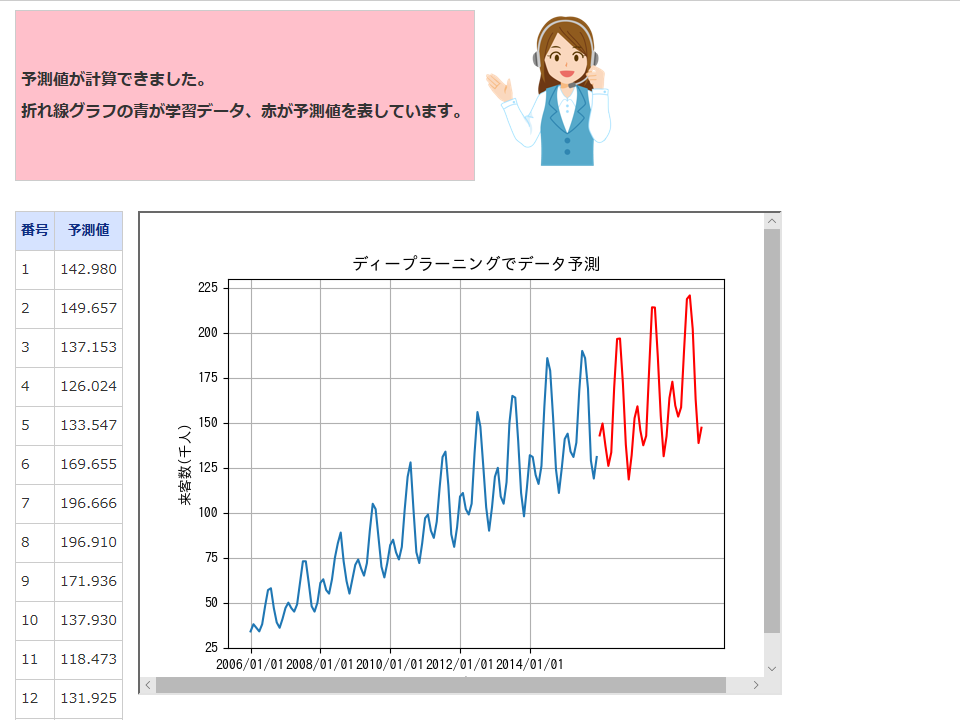
「予測結果の表示」画面では、以下のように予測値が表示されます。 (ディープラーニングの場合、内部で乱数を利用しているため、毎回多少異なる予測値になります。) 「予測結果をダウンロード」をクリックすると、予測値がExcel形式でダウンロードされます。また、折れ線グラフも表示されます。 青が実測値、赤が予測値です。
最後に、「トップページに戻る」をクリックすると、トップページに戻ります。
月々の来客数の予測結果データ
| 年月 | 予測値 |
|---|---|
| 2016年1月 | 142.980 |
| 2016年2月 | 149.657 |
| 2016年3月 | 137.153 |
| 2016年4月 | 126.024 |
| 2016年5月 | 133.547 |
| 2016年6月 | 169.655 |
| 途中省略 | |
| 2018年10月 | 163.108 |
| 2018年11月 | 138.749 |
| 2018年12月 | 147.294 |
このデータの場合、統計データ解析では、季節変動の有無や周期を入力した上で、以下のような特徴があります。
一方、ディープラーニングでは、これらの特徴を勝手に見つけています。
データ設定の注意点
詳細設定

「データ設定」画面で「詳細設定を表示する」をクリックすると、データ設定のプルダウンメニューが表示されます。 初期設定では、以下のような設定になっていますが、プルダウンメニューで簡単に変更できます。
- 数字(または日付)の列は、数量(または日付)と見なされ、文字や記号が混じっていれば、その行は取り除かれます。
- 文字や記号の列は、カテゴリーと見なされ、数字が混じっていてもカテゴリーと見なされます。
- 空欄は「データなし」と見なされ、その行は取り除かれます。
基本的に、数字は数量と見なされますが、設定するとカテゴリーと見なすことができます。 例えば、製品番号や社員番号は、数字であってもカテゴリーです。
- 1.男性
- 2.女性
上記のようなアンケート項目の回答を、Excelに1や2と入力した場合、この数字はカテゴリーと見なすべきです。
- 1.つまらない
- 2.ややつまらない
- 3.やや面白い
- 4.面白い
上記のようなアンケート項目の回答を、Excelに1~4と入力した場合、この数字は数量と見なしてもカテゴリーと見なしてもよいでしょう。数量と見なすと、「4×つまらない=面白い」という無意味な情報がある反面、「つまらない < 面白い」という意味のある情報が得られます。
基本的に、文字や記号はカテゴリーと見なされますが、設定するとゼロや「データなし」と見なすことができます。
例えば、人数の項目で、該当者なしを「-」と表した場合、文字や記号をゼロと見なすように設定します。 また、人数の項目で、不明を「-」と表した場合、文字や記号を「データなし」と見なすように設定します。
基本的に、空欄は「データなし」と見なされますが、設定するとゼロや特別なカテゴリーと見なすことができます。
例えば、人数の項目で、該当者なしを空欄で表した場合、空欄をゼロと見なすように設定します。
また、平日・休日の項目で、平日は空欄、休日は「休日」と表した場合、空欄を特別なカテゴリーと見なすように設定します。
3つ以上の識別
目的変数が3つ以上の場合

「問題の選択」画面で「確率を予測したい」を選択した場合、「項目の選択」画面で「何を予測しますか」(目的変数)は、基本的に0や1(真理値)の項目を選びますが、カテゴリーを選ぶこともできます。
もし、「何を予測しますか」(目的変数)として選んだカテゴリーが3種類であれば、3つの予測確率が計算されます。 例えば、何色のスマートフォンが売れるかを予測する場合、項目「色」のカテゴリーが「白」、「灰色」、「黒」の3種類ならば、「予測結果の表示」画面では「色=白」、「色=灰色」、「色=黒」の3列にそれぞれの予測確率が表示されます。
Excelファイル作成の際の注意点
エラーにならないためのExcelデータの作り方

- 1. 空欄のみの列が最初や途中にあり、空欄を「データなし」と見なす設定の場合、すべての行が削除され、データが少なすぎるというエラーが発生します。 空欄のみの列が最初や途中にあるなら、その列を削除しておいてください。
- 2. すべて同じ数量またはカテゴリーの列は、学習データとして無意味なので、その列を削除しておくか、「項目の選択」画面で「何から予測しますか」(説明変数)をオフにしてください。
- 3. すべて異なるカテゴリーの列は、学習データとして無意味なので、その列を削除しておくか、「項目の選択」画面で「何から予測しますか」(説明変数)をオフにしてください。
- 4. 数字と文字や記号が混在している列については、最初に数字が見つかれば数量と見なされ、文字や記号は削除され、最初に文字や記号が見つかればカテゴリーと見なされ、数字もカテゴリーと見なされます。数字と文字や記号が混在している列があるなら、「データ設定」画面で「詳細設定を表示する」をクリックし、設定が意図したものか確認し、必要に応じて変更してください。
※ ピーシーキッドアナライザーにExcelファイルをアップロードすると、自動的にデータ設定が行われますが、上記のような場合はエラーが発生したり、意図しないデータ設定になります。 あらかじめ列を削除したり、途中でデータ設定をしてください。
